Chapter1. RNN 기반 자연어 처리
➜ Recurrent Neural Network (RNN)
RNN개요 (Recurrent Neural Network)
- 히든 노드가 방향을 가진 엣지로 연결되어 순환구조를 이루는 신경망모델
- 음성, 텍스트 등 순차적으로 등장하는 데이터 처리에 적합한 모델
- 하나의 파라미터 쌍(weights, bias)을 각 시간대 데이터 처리에 반복 사용
- 시퀀스 길이에 관계없이 input과 output을 받아들일 수 있는 네트워크 구조
➜ 다양한 문제에 적용 가능한 장점


RNN 활용분야
• Image/Video Captioning
• Sentiment Classification
• Machine Translation
• POS Tagging
• Language Modeling
• Image/Music Generation (작곡 등)
• Conversation Modeling (챗봇)
• Speech Recognition
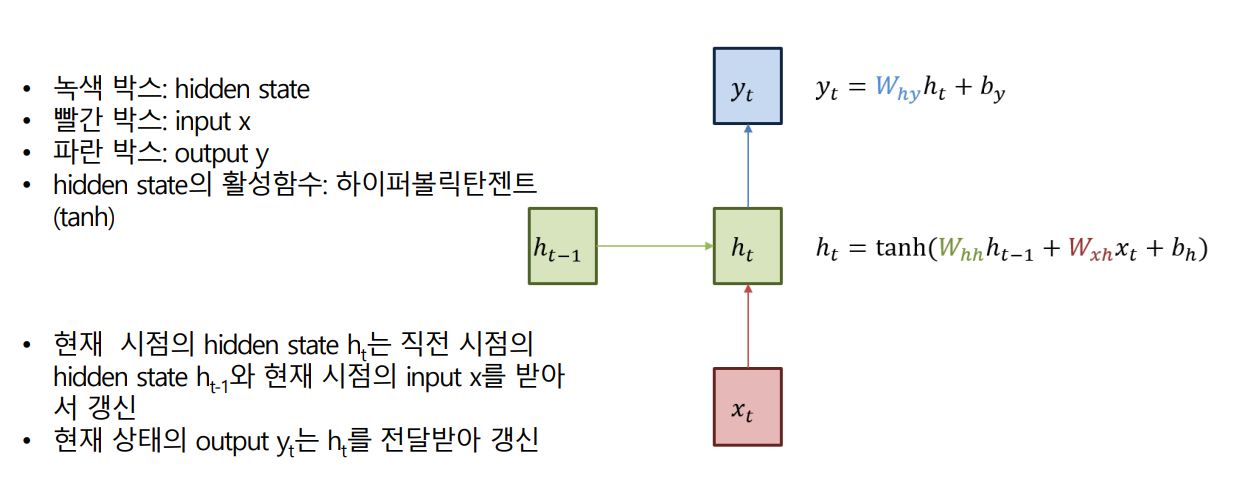
RNN 구조
하이퍼볼릭 탄젠트 함수 (쌍곡탄젠트, tanh)
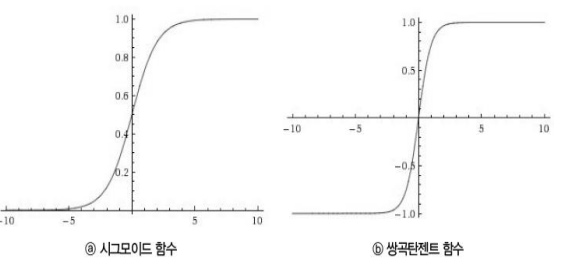
= 실수 범위의 입력값을 받아 (-1, 1) 사이의 출력 값으로 변환
- 임의의 입력값을 절대값 1 미만 값으로 변환, 값의 범위를 제한하는 블로킹 효과
- 기울기가 양수, 음수 모두 나올 수 있기 때문에 시그모이드 함수보다 학습 효율성이 뛰어남
- 입력 절대값이 커지면 출력값이 1 또는 -1로 수렴
- 시그모이드 함수보다 출력값 범위가 넓기 때문에
- 출력값의 변화폭이 더 큼 > 기울기 소멸
➜ (Gradient Vanishing) 현상이 더 작음

- RNN의 hidden layer 계산
- 자연어처리에서 RNN의 입력 Xt는 단어 벡터
- 단어 벡터의 차원 : d
RNN - 품사태깅 (POS Tagging)
- 같은 단어라도 문장 내 순서에 따라 품사가 달라질 수 있다
- 형태소분석의 기술적 이슈: 모호성


품사태깅은 분류문제

RNN 동작 – 품사태깅 학습 과정
- 정답값(target)과 모델의 예측 값(prediction)을 비교하여 그 두 값의 차이를 줄여나가는 과정
- 학습 과정을 거치면서 Whh , Wxh , b의 값을 최적화

RNN 동작 - 감성분석

기본 RNN의 문제점 (바닐라 RNN)
- 긴 시퀀스를 가진 입력이 들어올 때 RNN의 성능이 저조
- 특정 시간대에 형성된 정보를 먼 시간대로 전달하기 어려움
- gradient vanishing, gradient exploding이 발생하여 모델이 최적화되지 않음
- 사람의 장기기억에 해당하는 요소가 RNN에서는 작동하기 어려움
= 두 단어 사의 거리가 먼 경우 gradient vanishing 문제 발생

Long Short-Term Memory (LSTM)
- 기본 RNN에서 나타나는 gradient의 소멸 및 폭주 현상 해소
- 정보의 장거리 전달이 가능하여 기본 RNN에 비해 우수한 문제 처리 능력
- RNN을 구성하는 기본 단위를 기존의 퍼셉트론에서 좀 더 복잡한 구조로 바꾸는 방법
- Cell State, Forget Gate(망각 게이트), Input Gate를 이용
LSTM의 구조
= 잊을 건 잊고, 살릴 건 살리는 구조
- RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우
➜ 역전파 시 그래디언트가 점차 줄어 학습능력이 크게 저하 (Vanishing Gradient Problem)
- LSTM은 RNN의 hidden state에 cell state (일종의 컨베이어 벨트) 를 추가하여 이를 해결 (별도의 저장 공간)
- LSTM은 forget gate, input gate를 이용하여 이전 정보를 버리거나 유지

* Gates

= 생성된 시그모이드 값이 0에 가까 울수록 입력값을 무시, 1에 가까울 수록 입력값을 활용하는 효과
➜ 0 means “let nothing through”
➜ 1 means “let everything through!”
LSTM 연산기호

LSTM 구조 – forget gate
- cell state는 일종의 컨베이어 벨트로 작동하여 이전 셀의 값이 변하지 않고 전달되기 쉬운 구조임
- forget gate : to decide what information we’re going to throw away from the cell state
- 생성된 시그모이드 값이 0에 가까울수록 입력값을 무시, 1에 가까울수록 입력값을 활용하는 효과
- 가령 forget gate에서, 시그모이드 값이 0.8일 경우
➜ 80%의 과거 정보만을 기억하고 20%의 정보는 망각함


LSTM 구조 – input gate
= 일종의 수도꼭지같은 역할
input gate: to decide what new information we’regoing to store in the cell state
1) sigmoid layer (called the “input gate layer”) decides which values we’ll update.
2) tanh layer creates a vector of new candidate values that could be added to the state.
3) 1) and 2) are combined to create an update to the state

LSTM 구조 – cell state 업데이트

- The old cell state update: Ct-1➜ Ct
- Multiply the old state by ft, forgetting the things we decided to forget. then add it∗
- This is the new candidate values, scaled by how much we decided to update each state value.
LSTM 구조 – hidden state 업데이트

1) Run a sigmoid layer which decides what parts of the cell state we’re going to output
2) Put the cell state through tanh (to push the values to be between −1 and 1) and multiply it by the output of 1), so that we only output the parts we decided to.
= 이런식으로 연산장치를 추가하여 기본 RNN 구조가 가진 단점을 해결할 수 있음
근데, 꼭 왼쪽에서 오른쪽으로 방향이 이동되어야할까?
Bi-directional LSTM
= 현재시점의 예측을 더 잘할 수 있도록 양방향 RNN 도입

- 과거 시점의 입력 뿐만 아니라 미래 시점의 입력으로부터 정보를 얻어야 할 경우
➜ 이전과 이후의 시점 모두를 고려해서 현재 시점의 예측을 더욱 정확하게 할 수 있도록 고안된 것이 양방향 RNN
- 양방향 RNN은 하나의 출력값을 예측하기 위해 기본적으로 두 개의 메모리 셀을 사용
- 첫번째 메모리 셀은 앞 시점의 은닉 상태(ForwardStates) 를 전달받아 현재의 은닉 상태를 계산 (주황색 메모리 셀)
- 두번째 메모리 셀은 뒤 시점의 은닉 상태(Backward States) 를 전달 받아 현재의 은닉상태를 계산 (초록색 메모리 셀)
- 이 두 개의 값 모두가 현재 시점의 출력층에서 출력값을 예측하기 위해 사용됨
Bi-directional LSTM이 필요한 경우
= 앞에서 뿐만 아닌 뒤에서 오는 정보도 필요한 경우
He said, “Teddy bears are on sale!”
"I can't believe that Teddy Roosevelt was your great grandfather!"
두 문장의 'Teddy'는 서로 다른 분류 (명사, 대명사)
두번째 문장에서 'Teddy'는 뒤의 단어 '루즈벨트'에서 정보를 얻어와야 함

언어 모델 (Language Model)
Language Model
= 앞 단어(문장의 일부)를 보고 다음에 출현할 단어를 예측하는 모델

Language Model(언어 모델)은 학습데이터에 따라 달라진다
= 어떤 학습데이터로 학습시키는 것이 정말 중요하다.

Statistical LM (N-gram Language Model) (통계 기반, 확률 기반 언어모델)
- These models use traditional statistical techniques like N-grams,
Hidden Markov Models (HMM) to learn the probability distribution of words.
(N개의 이전 시점 단어를 통해 단어 예측)
"오늘 서울 날씨가 OOO"
오늘 + 서울 + 날씨 라는 시퀀스들을 모두 합쳤을 때 가장 많이 나온 단어로 예측
= ex) 오늘 서울 날씨가 좋아요
(마르코브 가정을 사용)
N-gram Language Model의 문제점 - Data Sparsity

4단어만 사용한 경우 가장 높은 확률값을 가지는 단어는 'BOOK'
그러나 '감독관(Procter)'이라는 단어까지 고려한 경우 가장 알맞은 단어는 'EXAM'
N을 크게 할수록 sparcity도 커진다!
➜ 아무리 거대한 말뭉치가 존재한다고 해도 세상의 모든 단어 시퀀스를 담고 있을 수는 없다.
N-gram Language Model의 문제점 - Storage
N을 크게 할수록 저장공간도 커진다!
➜ 세상의 모든 단어의 시퀀스 데이터를 저장할 수는 없다!
신경망 기반의 LM - RNN Language Model (신경망 기반 언어모델)
- These are new players in the NLP town and have surpassed the statistical language models in their effectiveness.
They use neural networks to model languages.
(HMM보다 더 고성능)

* Ex) Obama style
오바마 연설문 데이터를 바탕으로 오바마 화법 스타일로 단어를 예측

* Ex) Shakespeare style

Language modelling using an RNN
A. Prepare a training set
- A LARGE corpus of text
- Language : Korean, English, other languages
- Domain : newspapers, emails, conversations/chats, novels/poems, …
B. Tokenize each sentence to build a vocabulary
- (≅ 형태소분석하여 사전 구축)
- Add additional tokens
- <BOS>, <EOS>, <UNK>, punctuation (. , ?, !, , …)

C. Map each word in the sentence using any encoding mechanism
D. Build an RNN model where output is the softmax probability for each word in thedictionary
시각화 예시

이 문장과 같은 학습데이터가 있을 때, what, will, the, fat 시퀀스를 순서대 로 모델의 입력으로 넣으면
➜ will, the, fat, cat 을 순차적으로 예측 하도록 학습됨
언어모델의 데이터 편향성과 위험성
= 언어모델 기술은 실제 사실과 만들어 낸 것을 구별할 수 없는 기술
= 학습 데이터에 기반한 본질적인 편향성이 있을 수 밖에 없음
GPT-2 Model Card 내용
https://github.com/openai/gpt-2/blob/master/model_card.md#out-ofscope-use-cases
GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
Code for the paper "Language Models are Unsupervised Multitask Learners" - GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
github.com
Sequence-to-Sequence
sequence-to-sequence (seq2seq) 적용 분야

seq2seq 모델
= 시퀀스 입력 데이터에 대해 적절한 시퀀스 출력을 학습하기 위한 모델
- 두개의 RNN을 이용해 모델링(Encoder-Decoder 모델)
- 입력 문장을 받는 RNN 셀이 인코더, 출력 문장을 출력하는 RNN 셀은 디코더
- 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 이 모든 단어 정보들을 압축해서 하나의 벡터로
➜ 컨텍스트 벡터 (context vector)
- context vector는 인코더 RNN 셀의 마지막 시점의 hidden state
- 인코더가 컨텍스트 벡터를 디코더로 전송하면 디코더는 컨텍스트 벡터를 받아서 단어를 하나씩 순차적으로 출력

- seq2seq에서 사용되는 모든 단어들은 임베딩 벡터로 변환 후 입력으로 사용
- 디코더에서 각 시점(time step)의 RNN 셀에서 출력 벡터가 나오면
- 해당 벡터는 소프트맥스 함수를 거쳐서 각 단어별 확률값으로 변환
- 그 때 가장 높은 확률 값을 가진 단어가 출력

seq2seq for machine translation
* 독 - 영 번역 구조

seq2seq 모델의 단점
- 하나의 고정된 크기의 벡터 (context vector)에 모든 정보를 압축
➜ 정보 손실
- RNN의 고질적 문제인 기울기 소실(vanishing gradient)이 발생
신경망 기계번역 (Neural Machine Translation, NMT)
= 대표적인 딥러닝 기반 기계번역
- The approach of modeling the entire MT process via one big artificial neural network (End-to-End fashion)

- 딥러닝을 이용한 번역 ➔ 인간수준으로 근접

- seq2seq 모델의 단점은 context vector 가 일종의 bottleneck이 되어 긴 문장에서 long-term dependency 문제 발생
(은닉층의 과거 정보가 마지막까지 전달되지 못하는 현상)
➜ 긴 문장을 번역할 경우 성능 하락
- 번역 시, 입력문장 내 특정 단어의 정보를 더 참조할 수 있도록 처리
➜ Attention mechanism으로 성능 개선
- Attention은 입력문장 내에 현재 출력될 단어와 관련된 부분에 가중치를 부여하는 기법

Attention

Attention 기법
Attention: 시퀀스 데이터 모델에 서 단어 간 거리에 무관하게 입력, 출력 간의 의존성을 보존해주는 기법

- 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한번 참고
- 전체 입력 문장을 동일한 비율로 참고하는 것이 아닌, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분에 더 집중 ➜ 디코더에서 t번째 단어를 예측하기 위한 어텐션 값(Attention Value)을 계산

Attention(Q, K, V) = Attention 값
Q = Query : t 시점의 디코더 셀에서의 은닉 상태 ( St )
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들 ( hi )
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
• 어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 계산 (가중치 매트릭스로 계산)
• 계산된 유사도를 가중치로 하여 키와 맵핑되어 있는 각각의 '값(Value)' 에 반영
• 유사도가 반영된 '값(Value)'을 모두 더해서 반환한다.

• 인코더의 소프트맥스 함수를 통해 나 온 결과값 (그림의 타원 부분) 은
➜ I, am, a, student 단어 각각이 출력 단어 를 예측할 때 얼마나 도움이 되는지의 정도를 수치화한 값
• 소프트맥스 결과값이 클수록 디코더 에서 출력 단어를 예측하는 데에 도움됨
• 각 입력 단어가 디코더의 예측에 도움이 되는 정도를 하나의 정보 (Attention Value)로 담아서 디코더로 전송
(초록색 삼각형 부분)
1) Attention score 계산

- 인코더의 시점(time step)을 각각 1, 2, ... N이라고 하였을 때 인코더의 은닉 상태(hidden state)는 h1 , h2 , ... hN
- 디코더의 현재 시점(time step) t에서의 은닉 상태(hidden state)를 St
- 인코더의 은닉 상태와 디코더의 은닉 상태의 차원이 동일 (예시에서 각 은닉상태의 차원수는 4)
- 시점 t에서 출력 단어를 예측하기 위해서 디코더의 셀은 두 개의 입력값을 필요로 함
➜ 이전 시점인 t-1의 은닉 상태 (hidden state)와 이전 시점 t-1에 나온 출력 단어
- Attention score : 현재 디코더의 시점 t에서 단어를 예측하기 위해
인코더의 모든 은닉 상태 (hi)가 디코더의 t-1 시점의 은닉 상태 St-1 와 얼마나 유사한지를 판단하는 스코어
- Dot product 연산으로 값을 계산 :디코더의 현 시점의 은닉 상태 St-1 를 전치(transpose)
인코더의 각 은닉 상태와 내적(dot product)을 수행

2) Attention distribution 계산 (by Softmax)
Attention Score에 Softmax를 적용, 확률분포를 얻음 ➜ Attention weight

- Attention score의 모음값인 e^t 에 softmax 적용
➜ 모든 값을 합하면 1이 되는 확률분포가 된다
- 이 값을 attention weight (어텐션 가중치) 𝜶^t 이라 고 한다.

3) Attention Value 계산
인코더의 각 은닉 상태와 attention weight를 가중합 ➜ Attention Value

- 어텐션의 최종 결과값을 얻기 위해서 각 인코더의 은닉 상태와 어텐션 가중치값 𝜶^t 을 곱한 후 모두 더한다
➜ 가중합(Weighted Sum)
- Attention Value (=디코더 t 시점의 context vector) a^t 는 다음과 같이 정의된다.
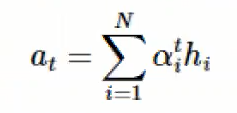
4) Attention concatenate

• Attention Value (어텐션 값) at 가 구해지면, at와 디코더의 현재 시점 t의 은닉상태 st 를 결합(concatenate)하여 하나의 벡터로 만든다
➜ Vt
• Vt 를 디코더의 출력 단어 예측 연산의 입력으로 사용하여 예측을 더 정확하게 할 수 있다.
5) 하이퍼볼릭 탄젠트 적용 (tanh)
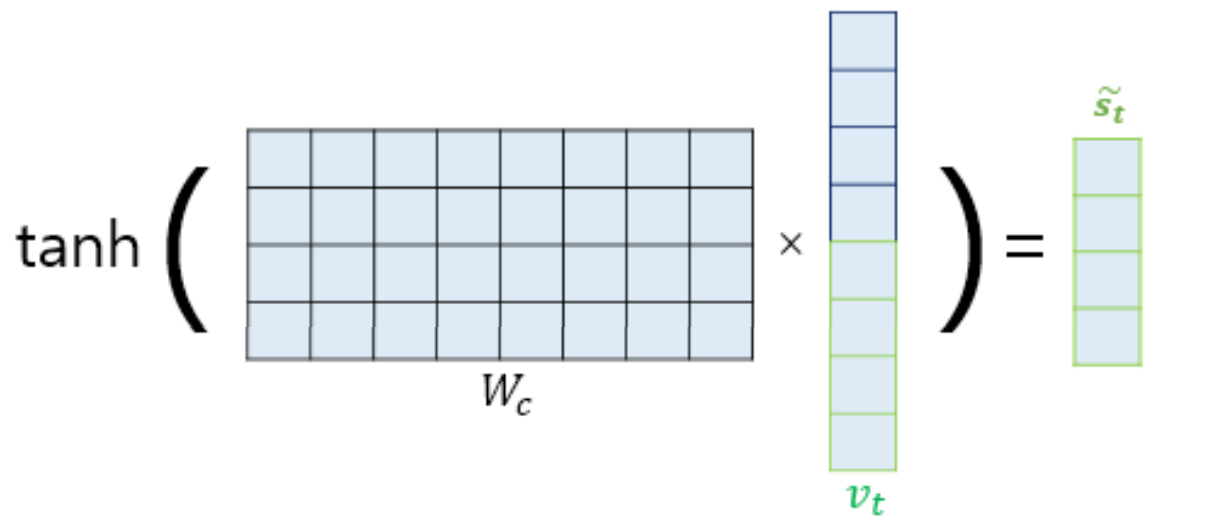
- Vt 를 바로 출력층으로 보내기 전에 가중치 행렬 Wc 와 곱한 후에 tanh 함수를 적용
➜ 이 값이 출력층의 입력값이 된다
- 비선형함수 tanh를 적용함으로써 학습을 더 깊게 할 수 있다
대표적인 Attention 기법
1. Bahnadau Attention (바나다우 어텐션)


decoder의 t 시점의 hidden state St 는
• 이전 시점의 hidden state St-1
• 이전 시점의 출력값 Yt-1
• 현재 시점의 컨텍스트 벡터 Ct 에 의해 계산된다
2. Luong Attention


• decoder의 t 시점의 hidden state St를 먼저 계산한 후에
(이전 시점의 hidden state St-1 과 이전 시점의 출력값 Yt-1로 계산)
• 계산된 St값을 이용하여 현재 시점 t의 컨텍스트 벡터 Ct 를 계산함
두 기법의 차이 =디코더에서 타임스텝으로 t시점을 사용하는 지 t-1 시점을 사용하는 지
'KT-Aivle School (AI) > 딥러닝' 카테고리의 다른 글
| [언어지능 딥러닝] BERT (0) | 2022.10.10 |
|---|---|
| [언어지능 딥러닝] Transformer (0) | 2022.10.09 |
| [언어지능 딥러닝] CNN for NLP (1) | 2022.10.07 |
| [언어지능 딥러닝] 워드 임베딩 (0) | 2022.10.05 |
| [언어지능 딥러닝] 텍스트 마이닝 (0) | 2022.10.05 |